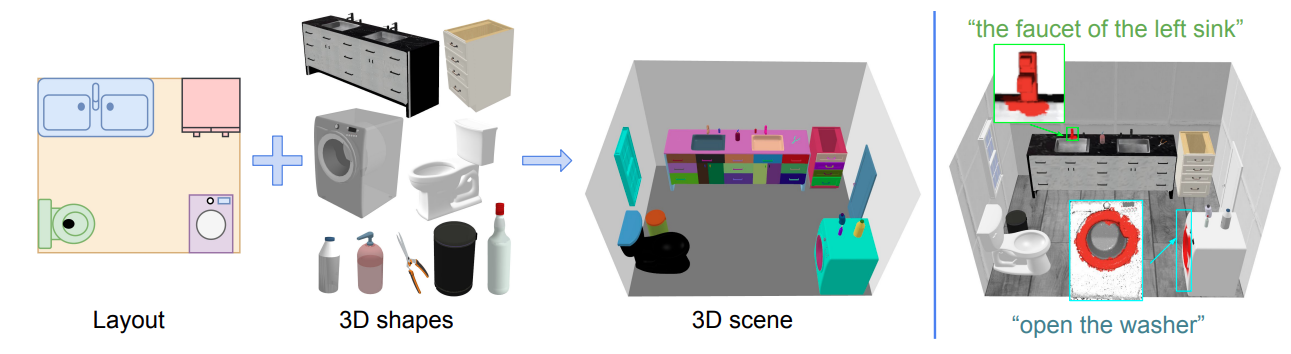
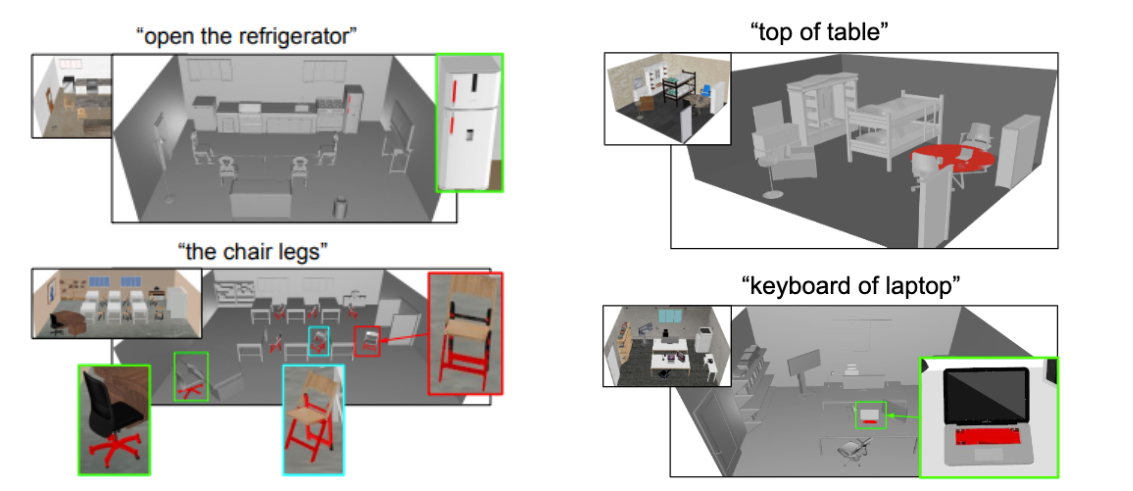
This paper aims to achieve the segmentation of any 3Dpart based on natural language descriptions, extending be-yond traditional object-level 3D scene understanding andaddressing both data and methodological challenges. Existing datasets and methods are predominantly limited toobject-level comprehension. To overcome the limitationsof data availability, we introduce the first large-scale 3Ddataset with dense part annotations, created through aninnovative and cost-effective method for constructing synthetic 3D scenes with fine-grained part-level annotations,paving the way for advanced 3D part understanding. On themethodological side, we propose OpenPart3D, a 3D-inputonly framework to effectively tackle the challenges of partlevel segmentation. Extensive experiments demonstrate thesuperiority ofour approach in open-vocabulary 3D understanding tasks at both the part and object levels, with stronggeneralization capabilities across various 3D datasets.